
Using pre-group-by in Tamr’s Recipe API when Mastering Customers to Multiple Levels
This article was written for versions after v2020.04.0 and at the time when the recommended release was v2021.006.0. Releases beginning with v2022.013.0 include record grouping in the user interface. Non-versioned APIs may change.
When producing a 360° view of a business' customers, the project team may want to master the data to different granularities. Typically this would be to three distinct levels:
- The site level, which differentiates by the specific offices/divisions/locations/business units of customers.
- The domestic level, which clusters all sites within a country under the legal/domestic entity (i.e. national headquarters).
- The global level, which consolidates all domestic entities as well as any other subsidiaries (e.g. from mergers and acquisitions) under the global parent organization (i.e. international headquarters).
For example, when mastering records for a customer such as Microsoft, the workflow would first produce views of all office/business unit locations within each city, then the legal entities within each country and finally a single cluster of all records under the global headquarter entity, which would include subsidiaries such as LinkedIn, Skype and GitHub. Once a cluster is produced at each of these three levels the records can be consolidated in order to obtain a single golden record for that entity at that level.
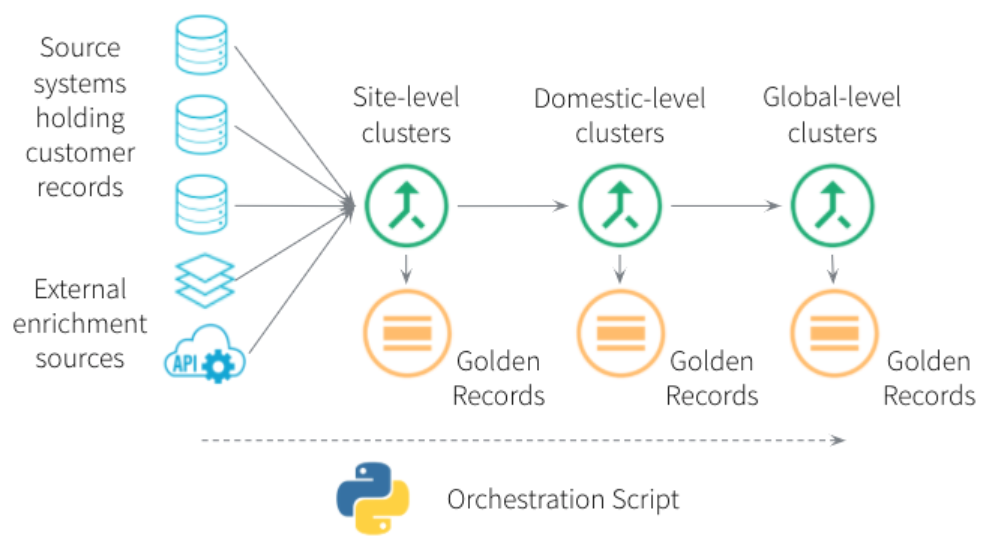
External enrichment data from sources such as Dun & Bradstreet can be incorporated in order to identify parent-child linkages that cannot be directly deduced from the source records themselves (e.g. due to recent merger and acquisition activity between companies with no fuzzy link in their customer records). Tamr’s data quality and enrichment services, available through the Tamr Cloud offering, can be used for address validation, geospatial data, email validation, telephone validation, and country code normalization. For an up-to-date list please see the <a href="public documentation or enquire with the Tamr support team ([email protected]).
When producing such a chained hierarchical workflow users may not want to redo the clustering work from the previous level(s) in each subsequent mastering project. Therefore, users can apply a pre-group-by statement on the previous mastering project’s published cluster IDs (i.e. persistentId).
To do this for the domestic-level users should first retrieve the recipe for that mastering project. Whilst on the “pairs” tab in the UI of that project, note down the recipe number that appears in the URL. For example: [https://URL/#/pairs/recipe/<recipeNumber>/]
Then, use the API GET /recipes/{id} to retrieve the current recipe. Admin users will need to specify the recipeNumber for this API call.

curl -X GET --header 'Accept: application/json' --header 'Authorization: BasicCreds <myCreds> 'https://<URL>/api/recipe/recipes/<recipeNumber>'
In the response body note down the lastModified version number specified near the top. Then, copy the response from "data" to a text editor (i.e. everything between and including the curly brackets).
In the text editor, users will find an undefined section called preGroupBy. Here, users need to define the groupingFields attributes and the fieldAggregationMap for all other attributes. The groupingFields should specify the exact match condition for the pre-group-by (e.g. the cluster key from the previous mastering project). The fieldAggregationMap defines how/what attributes get aggregated into array strings.
All ML attributes have to be listed in either the groupingFields or the fieldAggregationMap. ML attributes in groupingFields and fieldAggregationMap must be disjoint (i.e. cannot appear in both). It is optional to include any non-ML attributes in the fieldAggregationMap (e.g. in order to display values in pair questions).
For example:
"preGroupBy": {
"groupingFields": [
"SITE_LEVEL_PERSISTENT_ID",
"origin_source_name"
],
"fieldAggregationMap": {
"CUSTOMER_NAME": "top(10, ...\"CUSTOMER_NAME\")",
"CUSTOMER_ID": "top(10, ...\"CUSTOMER_ID\")",
"UltimateOwnerLegalName": "top(10, ...\"UltimateOwnerLegalName\")",
"FULL_ADDRESS": "top(10, ...\"FULL_ADDRESS\")",
"ADDRESS_LINE1": "top(10, ...\"ADDRESS_LINE1\")",
"ADDRESS_LINE2": "top(10, ...\"ADDRESS_LINE2\")",
"CITY": "top(10, ...\"CITY\")",
"COUNTRY": "top(10, ...\"COUNTRY\")",
"WEBSITE": "top(10, ...\"WEBSITE\")",
"PHONE_NUMBER": "top(10, ...\"PHONE_NUMBER\")",
"TAX_NUMBER": "top(10, ...\"TAX_NUMBER\")"
},
"rootEntityIdsSampleSize": 10
},
Here, we apply the pre-group-by on the site level’s persistent ID (i.e. the published persistentID is schema mapped to SITE_LEVEL_PERSISTENT_ID) and the origin dataset source name (i.e. origin_source_name), hence replicating the clusters from the site-level mastering project for the domestic-level’s pair questions. All other attributes are aggregated with a top(10, ... [attribute]) function which lists the top ten most frequent distinct values (the specified number can be adjusted).
Other possible aggregation functions include:
"TAX_NUMBER": "collect_set(...TAX_NUMBER)",
"ADDRESS_LINE1": "collect_subset(20, ...ADDRESS_LINE1)",
"PHONE_NUMBER": "collect_list(...PHONE_NUMBER)",
"WEBSITE": "first(...WEBSITE)"
Also view our public docs with general documentation on aggregation functions.
The rootEntityIdsSampleSize value defines the sample size of record IDs to keep per group. This sample size is used for auto-mapping labels, low latency matching and a future UI feature (in development at the time of writing this article).
Users can then copy the edited data body (i.e. everything between and including the curly brackets) and apply it to the API PUT /recipes/{id}. Admin users will also need to specify the recipeNumber and lastModified version number previously noted.

If users are unsure about the formatting of the modified json, they can verify this using this JSON validator.
Once the recipe has been successfully updated (i.e. response code in the 200s), users should refresh the “manage pair generation” window in the browser. Then, start the “estimate counts” job in the “manage pair generation” window. If this job succeeds the recipe was correctly updated. Users can now proceed with “generate pairs” :)
Pair questions in the domestic-level project will now reflect the clusters already identified in the previous site-level mastering project, hence leveraging all previous work. This includes all curated/verified clusters. If multiple sources are grouped together the pair question will identify this as having “groupedSources”.
Once the new clusters are generated all source records will be exploded out again to the original number of records, but now clustered to the new granularity of that project (e.g. domestic-level). The cluster page will always display individual source records in their respective clusters, not the “groups” of records.
This process can be applied to any mastering project where a pre-group-by can add efficiency to the overall mastering workflow. For example, to reduce the number of comparisons by leveraging the output of a previous/chained project or to take care of any exact match conditions before having the ML model address all fuzzy match comparisons.
Updated almost 2 years ago